먼저 Hello Wolrd 출력부터 해보려고 한다
마찬가지로 아래 2가지 방식으로 구현할 것이다.
| 1) 이미 만들어져있는 이미지 사용 2) Docker File을 통한 커스텀 이미지 생성 |
1) 기존 이미지 사용
https://hub.docker.com/ 에 가면 다양한 도커 이미지들을 볼 수 있다.
그중에서 도커 공식이미지인 Hello-world 이미지를 살펴보자

아무런 태그를 달지않으면 latest 태그가 받아질 것이고,
어떤 태그들이 있는지도 확인할 수 있다.

기본 이미지, 사용방법 등의 설명페이지가 있지만,
간단한 Hello-world 이미지이기때문에 바로 수행해볼 것이다.
sudo docker run hello-world
위의 간단한 명령어로, 사용 가능하다.
어떤 동작원리인지 모르는 블랙박스 형태여도, 사용할수 있다는게 장점이기도 하다.
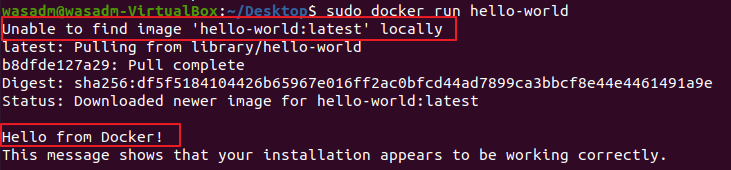
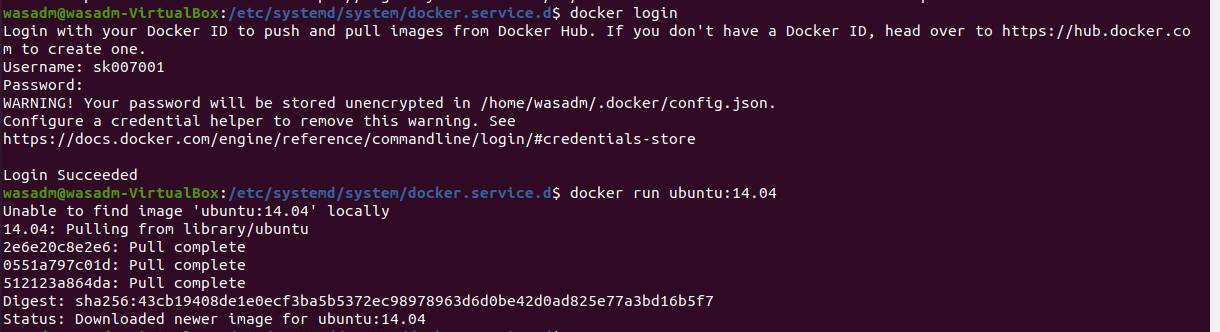
run 명령어 수행시, Host PC에 이미지가 없어서 hub.docker 에서 이미지를 가져오는 모습이다.
Tag는 따로 지정해주지 않아, Default 인 latest 태그 이미지를 가져온다.
2) Docker File을 통한 커스텀 이미지 생성
먼저, Docker File 기본 구성에 대해 알아보자.
- From : base 이미지 지정
- ADD : 로컬,URL에서 파일이나 디렉토리를 컨테이너로 복사할때 사용
- COPY : ADD와 같은 기능이나 URL에서 가져올 수 없고, 압축파일도 해제없이 그대로 복사된다.
- LABEL : key=value의 기타 정보를 이미지에 심을 떄 사용
메타정보라고 넘어갈 수 있지만, 후에 쿠버네티스 사용 시 필요한 항목이니 유의
- ENV : 컨테이너에 적용할 환경변수 사전 정의
- ARG : 컨테이너 빌드시 사용할 아큐먼트 정의
- EXPOSE : 호스트와 연결할 포트 번호를 설정
- VOLUME : 호스트 디렉토리 마운트.
- RUN : 이미지 생성 시, 실행할 Command 지정
- CMD : 이미지 생성 이후, 처음으로 실행될 명령어. 여러개의 CMD 작성시, 마지막 CMD만 적용
- ENTRYPOINT : 이미지 생성 이후 실행될 명령어.
※ Command 문법
RUN/CMD/ENTRYPOINT ["command","parameter1","parameter2"]
※ CMD와 ENTRYPOINT 차이
ENTRYPOINT는 DockerFile에 지정된 그대로 명령을 수행하지만,
CMD는 인자값을 주게되면 해당 인자값으로 명령을 수행한다.
Hello World DOCKER FILE
- Dockerfile 생성
FROM alpine:3.14 # 우분투 말고, 도커 베이스이미지로 많이쓰이는 알파인을 사용하였다. ( 5MB 정도 )
CMD ["echo","Hello-World"] # 이미지 생성후 Hello World 출력

- 이미지 빌드
sudo docker build -t sk007001/hello-world:v0.1 /docker
-t <이미지명:tag명> <Dockerfile 위치> 명령어로, Dockerfile 기반의 이미지를 태깅하여 빌드하였다.
앞의 sk007001은 개인 hub 저장소 위치를 명시해주었다.

- 이미지 확인 및 컨테이너 생성
sudo docker images

sudo docker run sk007001/hello-world:v0.1

- 해당 Image 저장소에 Push
잘 동작하는것을 확인했으니, 저장소에 Push 하려한다.
sudo docker push sk007001/hello-world:v0.1


'IT > 도커도커' 카테고리의 다른 글
| (6-1) 도커 內 Rest Api 서버 구성하기 ( Python ) (0) | 2021.08.11 |
|---|---|
| (5) 도커 Hello World - 웹페이지 (0) | 2021.07.22 |
| (3) 도커 명령어 (0) | 2021.07.19 |
| (2) 컨테이너 및 도커 (0) | 2021.07.14 |
| (1) Ubuntu에 도커 설치하기 (0) | 2021.06.30 |