GitHub에서 설치파일 다운로드 - github.com/scouter-project/scouter/releases/
Server, Agent, Client 모두 설치 예정이므로 All 버전 다운로드
-> 압축 풀어주면 설치는 완료

1) Server 구동
□ 설치 디렉토리/server/conf/Scouter.conf 파일 수정
- 아무것도 작성이 안되어있어, Default 로 동작하겠지만, 수정이 필요하면 옵션 수정
TCP, UDP Port 및 DB,log 저장 Path
더보기
# Agent Control and Service Port(Default : TCP 6100)
net_tcp_listen_port=6100
# UDP Receive Port(Default : 6100)
net_udp_listen_port=6100
# DB directory(Default : ./database)
db_dir=./database
# Log directory(Default : ./logs)
log_dir=./logs
□ 설치 디렉토리/server/conf/Start.bat 수행


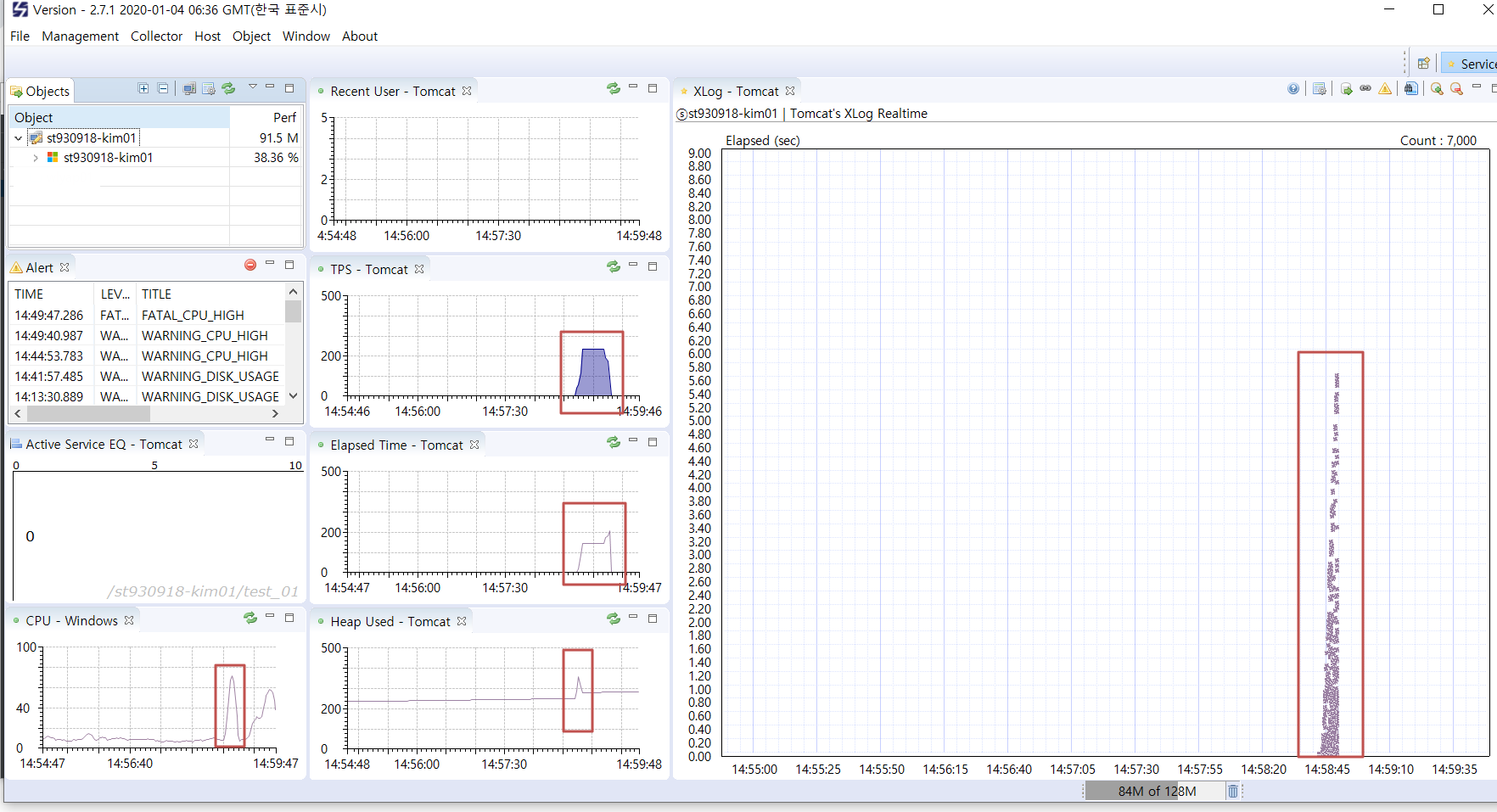
2) Client로 접속 확인
- Default Port : <server>:6100 Port
- Default ID/PWD : admin/admin

- 서버는 가동되었으나, 수집되는 정보는 없는 상태

3) Agent 구동하여 데이터 수집하기
3-1) Host Agent
□ 설치폴더/agent.host/conf/scouter.conf 수정
# Default Setting
### scouter host configruation sample
#net_collector_ip=127.0.0.1
#net_collector_udp_port=6100
#net_collector_tcp_port=6100
#cpu_warning_pct=80
#cpu_fatal_pct=85
#cpu_check_period_ms=60000
#cpu_fatal_history=3
#cpu_alert_interval_ms=300000
#disk_warning_pct=88
#disk_fatal_pct=92
|
// Admin 서버 정보
net_collector_ip=127.0.0.1 // 데이터를 전송받을 Admin Server IP
net_collector_udp_port=6100 // UDP Port ( 기본 6100 )
net_collector_tcp_port=6100 // TCP Port ( 기본 6100 )
// CPU 알림 여부
#cpu_warning_pct=80 // Warning %
#cpu_fatal_pct=85 // Fatal %
#cpu_check_period_ms=60000 // CPU 수집 주기
#cpu_fatal_history=3 // Fatal 알림 누적 카운트
#cpu_alert_interval_ms=300000 // CPU 알림 주기
// DISK 알림여부
#disk_warning_pct=88 // Warning %
#disk_fatal_pct=92 // Fatal %
□ 설치폴더/agent.host/host.bat 수행
OS 정보 수집되는것 확인

3-2) Java Agent
□ Java agent는 단독실행이 아니라, 인스턴스에 붙어서 수행됌
□ 설치폴더/agent.java/conf/scouter.config 수정
### scouter java agent configuration sample
obj_name=test_01
net_collector_ip=127.0.0.1
net_collector_udp_port=6100
net_collector_tcp_port=6100 |
□ Tomcat 실행옵션에, Scouter 추가.
Eclipse VM Option에 하기 내용 추가
-javaagent:"D:\scouter-all-2.7.1.tar\scouter\agent.java/scouter.agent.jar"
-Dscouter.config="D:\scouter-all-2.7.1.tar\scouter\agent.java/conf/scouter.conf"
□ 수집하는것 확인